

弱监督文字检测与识别(持续更新)
关于弱监督文字检测与识别的论文阅读
Language Matters: A Weakly Supervised Vision-Language Pre-training Approach for Scene Text Detection and Spotting
来源:ECCV2022
链接:https://arxiv.org/pdf/2203.03911.pdf
代码:https://github.com/bytedance/oclip
摘要
视觉语言预训练(Vision-Language Pre-training, VLP)技术通过联合学习视觉和文本表示,极大地促进了各种视觉语言任务的完成,由于场景文本图像中丰富的视觉和文本信息,视觉语言预训练技术对光学字符识别(OCR)任务有直观的帮助。然而,由于实例级文本编码和图像-文本对(即图像和捕获的文本)获取的困难,这些方法不能很好地处理OCR任务。本文提出了一种弱监督前训练方法oCLIP,该方法通过联合学习和对齐视觉和文本信息来获得有效的场景文本表示。网络包括一个图像编码器和一个字符感知的文本编码器,分别提取视觉和文本特征,以及一个视觉文本解码器,对文本和视觉特征之间的交互进行建模,以学习有效的场景文本表示。通过对文本特征的学习,预训练模型能够很好地感知图像中的文本。此外,这些设计能够对弱注释文本(即图像中没有文本边框的部分文本)进行学习,极大地缓解了数据注释约束。ICDAR2019-LSVT中对弱注释图像进行的实验表明,我们的预训练模型在将其权值转移到其他文本检测和识别网络时,F分数分别提高了+2.5%和+4.8%。此外,所提出的方法在多个公共数据集上始终优于现有的预训练技术(例如,Total-Text和CTW1500的性能分别为+3.2%和+1.3%)。
简介
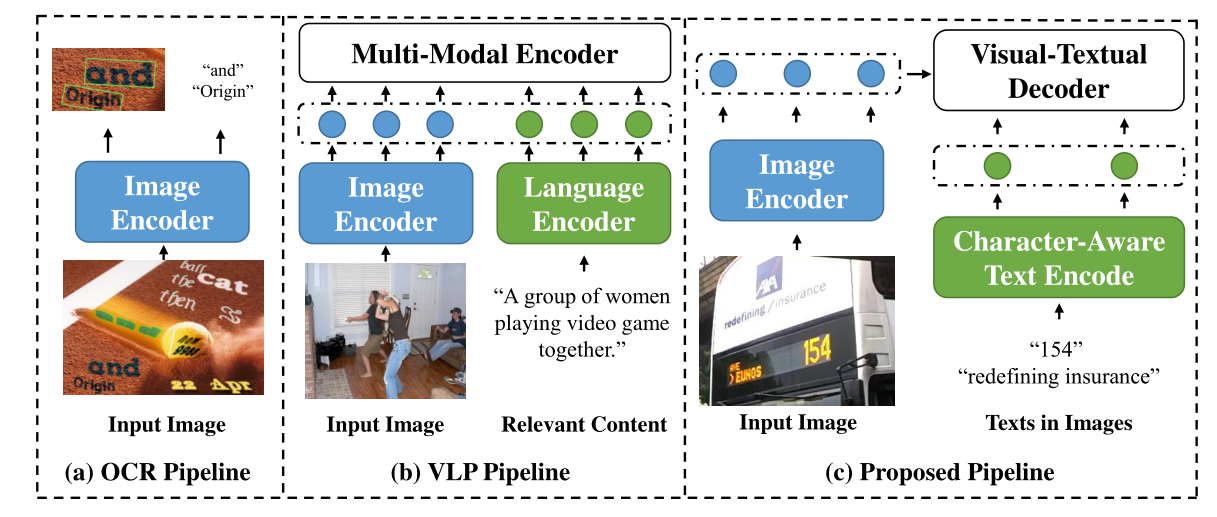
OCR只关注图像的视觉特征。此外,一般的VLP模型从输入图像和相应的句子级文本中提取图像和语言特征,并通过多模态编码器对所有视觉和文本特征之间的交互进行建模。不同的是,oCLIP从图像中的文本实例中提取实例级文本特征。它对每个文本实例和其提取的图像特征之间的交互进行建模,这些图像特征只能用弱监督进行训练(即图像中没有文本边框的部分文本)。我们的预训练模型权重可以直接转移到各种场景文本检测器和检测器,具有显著的性能改进。
VLP方法在应用于OCR任务时通常会受到两个约束。(1) VL任务中的每个图像通常与一个句子或段落相关联,其中单词或短语按照阅读顺序排列。相反,OCR任务中的图像通常包含许多文本实例,每个文本实例由一个或多个标记组成。一个文本实例中的标记通常彼此密切相关,来自不同文本实例完全无关。(2)大多数VLP模型从图像-文本对中学习,图像和文本在内容层面相互关联(如图像和图片解释)。这些与内容相关的图像-文本对可以很容易地从web、社交媒体等获取,已经被证明对各种VL任务是有效的。相比之下,OCR任务的目的是检测和识别图像中的文本实例。与VL任务相比,图像-文本对(即其中的图像和文本)更难获得,需要昂贵和低效的注释。
贡献:
1.引入了一个端到端可训练的预训练网络,允许利用语言监督学习有效的视觉文本表示。
2.设计了一个字符感知的文本编码器和视觉文本解码器,可以提取有效的实例级文本信息,并从部分文本转录中学习,而不需要文本边界框。
3.在多个公共数据集上的大量实验表明,所提出的弱监督预训练网络在各种场景文本检测和定位数据集上具有优越的性能。
方法
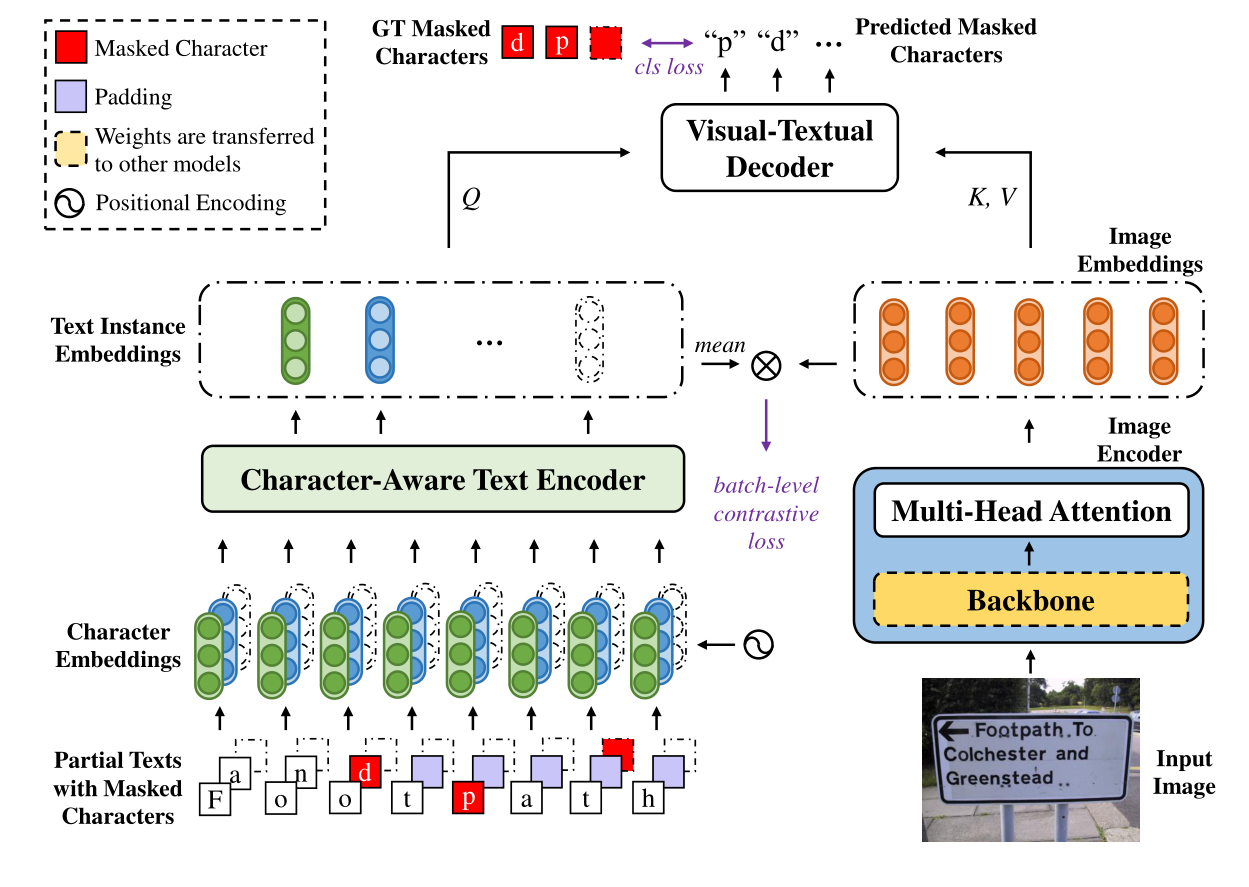
给定一个输入图像,图像编码器首先提取视觉特征。同时,将每个文本实例中的字符转换为字符嵌入,字符感知的文本编码器进一步从字符嵌入中提取文本实例嵌入。可视文本解码器对文本实例嵌入和相应图像嵌入之间的交互进行建模。在训练过程中,每个文本实例中的一个随机字符将被屏蔽,并通过预测被屏蔽字符来优化整个网络。
Character-Aware Text Encoder

具有一般句子级文本编码器和所提出的字符感知文本编码器的模型中获得的注意图。与一般的文本编码器相比,提出的字符感知文本编码器更好地照顾文本区域,导致更好地学习网络骨干的场景文本视觉表示
Visual-Textual Decoder
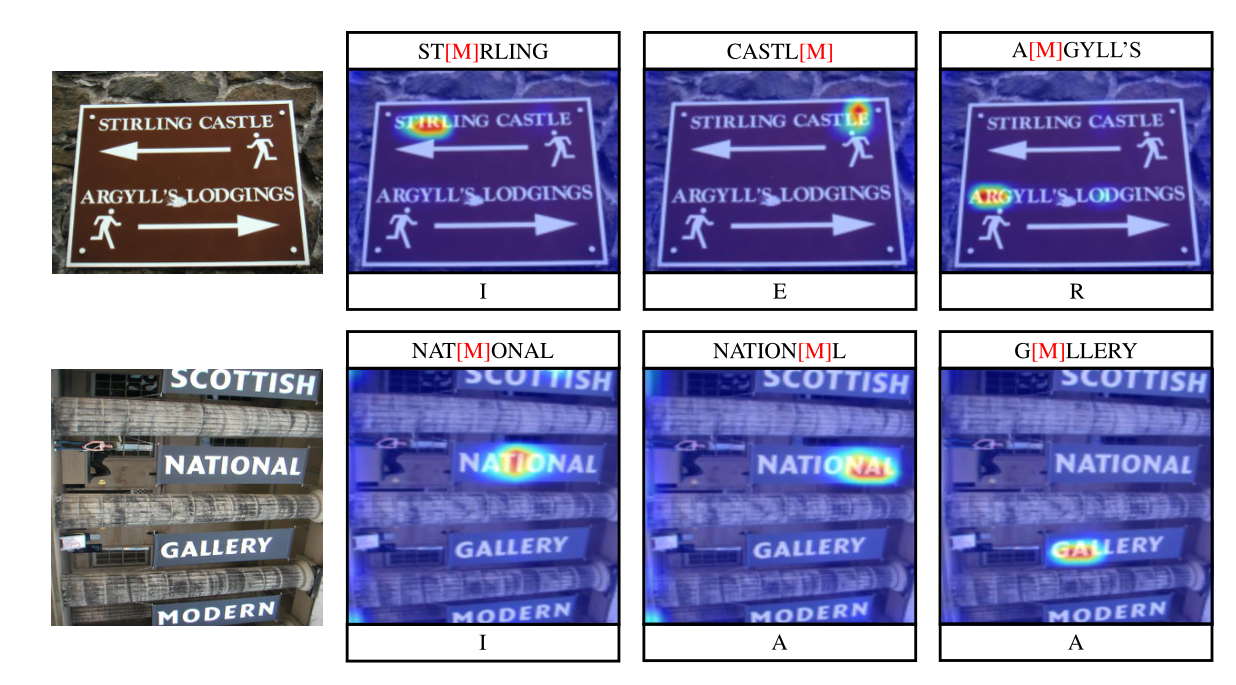
视觉-文本解码器不仅能预测出掩蔽字符(例如,“I”代表“ST[M]RLING”),而且能很好地处理图像中对应的掩蔽字符区域。可以看到,提出的解码器对齐视觉和文本特征来预测被掩盖的字符(而不是单独使用文本信息),证明了提出的视觉-文本解码器的有效性。
网络优化:
训练输入为图片I与文本实例T(带有mask的ymsk)通过预测掩码字符p(I,T)来进行优化,将掩码预测作为一个分类问题,使用交叉熵损失函数。
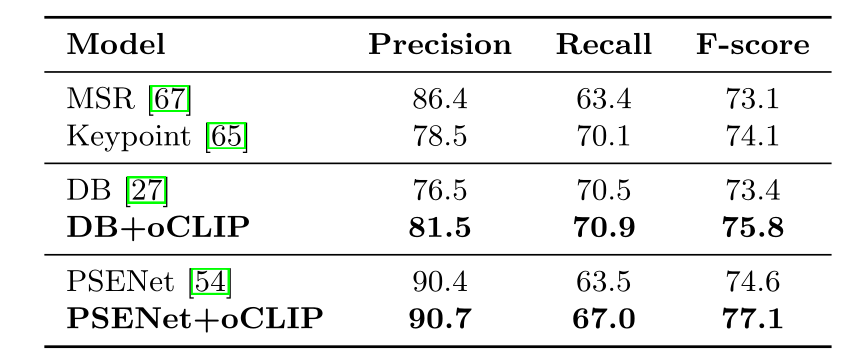
实验

结论
本文提出了一种用于场景文本检测和定位任务的弱监督前训练技术。它侧重于从图像和文本转录的视觉和文本信息的联合学习,以增强视觉表征的学习。它设计了一个字符感知的文本编码器和可视化文本解码器,提高了oCLIP在不使用文本边框的情况下仅从部分文本转录学习的可行性。实验结果表明,该方法能够有效地学习弱注释场景文本数据集,极大地缓解了数据采集的挑战,显著促进了不同场景文本检测器和检测器的发展。